Website Global Policy
The Alert Logic Managed Web Application Firewall (WAF) Website Global Policy page includes the following sections. Click on the link to go to the corresponding section to learn more:
To access the Website global policy section in the WAF management interface:
- On the left panel, under Services, click Websites.
- On the Websites page, click the website you want to manage.
- Under WAF, click Policy, and then scroll down to the Website policy section.
If you want to see all the settings on the Policy page, on the upper-right corner, change the Display preset to Advance.
To save configuration changes or edits you make to any features and options, you must click Save on the lower-right of the section or page where you are making changes. Click apply changes on the upper-left corner of the page, and then click OK. Your changes will not be stored if you do not properly save your changes.
Validate static requests separately
The Static content policy allows requests without parameters based on file extension (i.e., .gif) and allowed path characters.
To define a static content policy enter or edit file extensions and allowed path characters.
- File extension
-
The file extension is defined as a list of comma separated values.
- Allowed path characters
-
Allowed path characters are defined by selecting them on a list.
The letter A denotes all international alphanumeric characters and other characters are represented by their glyph, their UTF-8 number and a description.
As static content is not supposed to have any parameters (hence the denotation "static") only requests without parameters
and with the method GET are validated against this rule.
It is possible to allow static requests in general.
| Allow all static requests
Radio button |
If selected, requests without parameters like requests for graphic elements, stylesheets, javascript, etc. are allowed in general. Allowing all static requests is faster but less secure as only input to web applications will be inspected when this option is enabled. |
| Validate static requests path and extension
Radio button |
If selected, requests without parameters like requests for graphic elements, stylesheets, javascript, etc. are validated using allowed path extension and allowed path characters. Default: |
| Allowed path characters
List of check boxes |
Allowed path characters are defined by selecting them on a the list which appears when activating the button . In the list the letter A denotes all international alphanumeric characters and other characters are represented by their glyph, their UTF-8 number and a description.
|
| Allowed static file extensions
Input field |
The file extension is defined as a list of comma separated values.
|
| Validate cookies for static requests
Check box |
Enable / disable validation of cookies for requests for static content. Default: |
URL path validation
The URL regular expressions filter matches URLs without parameters on a proxy global basis. If a request matches any of the defined regular expressions, it will be marked as valid by WAF and forwarded to the back-end server.
For examples of global URL regular expressions, please refer to Examples of global URL regular expressions.
Full match is implied for each regular expression, meaning that each will match from the start to the end of the request (a caret ^ and dollar $ will be appended if not already present).
| Negative validation
Check box |
Select or clear to enable validation of the path element of the URL against negative signatures. Paths not matching attack signatures will be allowed. |
| Positive validation
Check box |
Select or clear to enable positive validation of the path element of the request URL. Paths matching one of the regular expressions in the list will be allowed. |
| Allowed path |
In the list enter one or more regular expressions defining the global path policy.
|
Denied URL paths
The URL regular expressions block filter matches URLs without parameters on a proxy global basis. If a request matches any of the defined regular expressions it will instantly be blocked.
Suppose for instance that a global paths policy rule allows all URL paths's with the extension ".php" but that you want to block access to all resources in the /admin directory - including subdirectories. To do that simply add the policy rule "/admin/".
The expressions are matching from left to right. Full match is not implied but matching always start at start of line. This implies that for instance the expression /admin will match any URI starting with /admin
| Denied path
Input fields |
In the list enter one or more regular expressions defining the global denied path policy.
|
|
Add predefined Drop-down list |
Select one of the following predefined regular expressions:
|
Query and Cookie validation
Depending on the web server and web application technology and design of the web applications on the back end web server cookie names and values may in some cases be parsed as part of a general request object with the risk that client request cookies may be used to bypass validation controls. It is therefore recommended that cookies are parsed and validated as an integral part of the client query. That is as request parameters.
WAF parses cookies and when learning is enabled the Learner maps cookie values as global parameters.
| Cookie validation enabled
Check box |
If enabled client request cookies will be parsed and validated as request parameters. Default: |
Validation
In the global parameters section, parameters which all or many URLs have in common can be added. For instance in many CMS systems an URL can be viewed in a printer friendly version by adding a specific parameter to the URL.
When adding parameters to the list the name of the parameter is interpreted by WAF as regular expressions. Like with the global URL-regular expressions full match from start to end is implied. The value can either be a regular expression or a predefined input validation class.
| Enable global parameter signature based negative matching
Check box |
Select or clear the check box Enable global parameter signature based negative matching to enable signature bases matching of parameter names and corresponding values. When learning is enabled for the website this option should be enabled as it ensures that parameters not being validated by positive policy rules are validated negatively and thus not rejected by default. |
| Enable global parameter regexp matching |
Select or clear the check box Enable global parameter regexp matching to enable global parameter regexp matching. |
| Name
Input fields |
In the list enter a regular expression matching the parameter name or names you want to match.
|
| Type
Drop-down list |
Input validation type.
|
| Update
Drop-down list |
Controls how the Learner handles the parameter. When update is set to |
| Value
Depends on |
Value for input validation.
When type is |
For examples of specifying global parameters using regular expressions please refer to Examples of global parameters regular expressions.
For more general examples using regular expressions for input validation please refer to Examples of regular expressions for input validation.
Full match is implied for each regular expression, meaning that each will match from the start to the end of the request (a caret ^ and dollar $ will be appended if not already present).
Headers validation
| Allow only RFC defined headers
Check box |
Enable / disable enforcement of strict HTTP compliant headers. If enabled, WAF will enforce strict HTTP header compliance according the RFC standards and deny any custom HTTP header sent in the request. Default: |
| Input headers validation rules
Check box |
The header validation policy rules allow for enforcing a combination of positive and negative validation rules on either specific named headers or all headers. "All" header rules also applies to specific named headers. For each header policy entry the options are:
|
Attack signatures usage
Two signature engines are available in Fortra WAF:
- Legacy Signature Engine: The original WAF signature engine. While detection capability is excellent, the Legacy engine allows for less granular discrimination – both in terms request element validation and source differentiation.
- Advanced Signature Engine: Utilizes a combination of signature confidence and connection trust to validate connections, adapts WAF Operating Mode from Detect to Protect based on Connection Trust, and includes HTTP header and file contents inspection.
Signature Engine
Toggle between Legacy and Advanced signature model.
Advanced Signature Engine
The Advanced Signature Engine employs a signature and validation model that is based on a combination of signature confidence and connection trust. Trusted connections are validated using signatures with a very low false positive risk, but if a connection proves to not be trustworthy because of attack activity, more sensitive signatures with a higher potential rate of false positives are included in the validation of HTTP requests from that specific connection.
In addition to mapping Signature Confidence level to Connection Trust, the WAF Operating Mode can automatically change from Detect to Protect based on Connection Trust. This feature is called Adaptive Protect Mode.
The Advanced Signature Model includes specific HTTP header inspection and file contents inspection capability.
Signature Confidence
Signatures are grouped in three confidence levels (High, Medium, and Low) based on how likely they are to trigger false positives. The higher the signature confidence the more known exploit content is required to be present in the HTTP request for the signature to match. The higher signature confidence would include special characters that often are required to inject the exploit code – like an apostrophe in SQLi exploits. For lower confidence signatures, presence of keywords may be enough to trigger the signature, and tend to trigger more false positives. Thus, lower confidence signatures also have a lower false negative rate and are more likely to detect attacks that are difficult to discern from normal activity.
Based on testing the signature model on real traffic data, more than 80% of detection across the three confidence levels is within the 90-confidence level. Each of the 80 and 70 confidence levels add around 10 percent-point marginal detection in return of a much steeper increase in false positives.
Initial signature confidence is configured by Sensitivity setting. The options are Standard sensitivity (use High confidence only), High sensitivity (use High and Medium confidence), and Very High sensitivity (use High, Medium, and Low). The default is Standard for trusted connections. However, for WAF user that prefer to trade a high increase in false positives for all connections for a small decrease in false negatives, the initial Sensitivity can be set higher. In most cases, a better option would be to change how fast specific connections are downgraded and validated using lower confidence signatures – without negatively affecting non-hostile connections.
Connection Trust
“Connections” (source IPs) are grouped in three trust levels (High, Medium, and Low) based on accumulated signature detection. Connections start at the highest possible trust level but as they trigger signature violations, they are downgraded to lower trust levels. The contribution of each violation to trust downgrade depends on the confidence of the signature. The higher the signature confidence the more trust is downgraded.
Attack activity is tracked across all website security profiles configured for the Advanced Signature Model on a WAF instance, but Connection Trust may be calculated differently for individual website security profiles depending on Trust Downgrade configuration. If Trust Downgrade is set to Fast, it takes less signature violations for a connection to be downgraded than if set to Medium. For website security profiles where Trust Downgrade is set to Off, Connection Trust is not downgraded regardless of connection attack activity.
Connection activity is tracked in run time memory and is currently not reset until a core restart – such as when applying changes to policy or proxy configuration.
Sensitivity
- What signature confidence level to initially use for non-downgraded connections
- Default: Standard
- Options
- Standard = 90 (highest confidence)
- High = 80
- Very High = 70
Trust Downgrade
- Amount of accumulated signature violations required for an IP to be downgraded
- Downgrade is progressive and is based on number of detected violations with higher confidence signatures contributing more heavily than lower confidence sigs
- Confidence 90 contributes 1.00 “downgrade ticks”
- Confidence 80 contributes 0.50 “downgrade ticks”
- Confidence 70 contributes 0.25 “downgrade ticks”
- Options (examples based on confidence level 90 sigs)
- Off = no downgrade, no cross-site contribution
- Standard = downgrade at 12 (step 1) and 17 (step 2) violations (with current logic)
- Fast = downgrade at 8 and 12 violations for step 1 and 2 respectively
To avoid inaccurately configured trusted proxy and X-Forwarded-For extraction to cause an internal load balancer to represent all external connections private IPs are currently exempt from downgrade.
Advanced Signature Class Exceptions
Violation action exceptions can be set for individual signature classes (SQL Injection, Code Injection, etc.).
- None: No exception
- Log: Log but do not block
- Pass: Ignore violation without logging
Interaction with other features
Signature confidence, sensitivity, and resulting connection trust feeds into other validation and protection features.
Adaptive Protect mode
UI Path: WAF > Policy > Basic operation > WAF operating mode definitions
- Move to protect mode for connections that are trust downgraded
- Only effective when website is flagged as tuned
- Options
- Low (default): use Protect mode for connections that have been downgraded to low trust
- Medium: use Protect mode for connections that have been downgraded to medium trust
- Off: Adaptive protect mode off
Streaming Inspection of Unlimited Request Body Size
UI Path: WAF > Policy > Web Applications > [web application]
- Enable streaming of unlimited size request body
- Configure deny/allow, parsing and validation signatures per content type
- Allow: Yes/No
- Parse (extract name/value pairs from payload): Yes/No
- Validation:
- Raw – use signatures intended for unparsed payloads
- Upload – use signatures intended for upload payloads
- Bypass – bypass request body without validation
Legacy Signature Engine
The Legacy Signature Engine uses the original Fortra WAF signatures and signature format. While it boasts excellent detection capabilities, it has certain limitations compared to the Advanced Signature Engine:
- Granularity: The Legacy engine offers less granular discrimination in both request element validation and source differentiation.
- Signature confidence: Unlike the Advanced engine, signatures in the Legacy engine are not rated by confidence levels.
- Request element grouping: Signatures are not grouped based on the request elements they apply to, which can affect the precision of threat detection.
Overall, the Legacy Signature Engine provides robust detection but lacks the refined control and adaptability of the Advanced Signature Engine.
Custom Signatures
Both signature engines allow for creating custom signatures. A custom signature is created in the custom signature table:
- Status: On/Off – enable or disable the signature
- Attack Class: Select attack class from the dropdown list
- Signature: RE2 compatible regular expression (no “lookaround”)
- Comment: Description of signature
- Tag: Tag to identify the signature by – like a CVE
Session and CSRF protection
WAF can protect against session hijacking and CSRF (Cross Site Request Forgery) by:
- Binding client IPs to session cookies by issuing a validation cookie containing a cryptographic token (a checksum) which validates session id + client IP + a secret for each client request.
- By binding forms to sessions and verifying the origin of the form through insertion of a form validation parameter containing a cryptographic token which proves that the action formulator (the system issuing the page containing a form with an action) knows a session specific secret.
- Additionally idle sessions are timed out in order to prevent users from staying logged in making them vulnerable to CSRF attacks.
When the web system issues a session cookie WAF detects it and issues a corresponding session validation cookie. In order to be able to identify the session cookie it is necessary to enter the name of the cookie containing the session id - i.e. PHPSESSID, JSESSIONID, ASPSESSIONID, SID.
An easy way to identify the session cookie name for the site you are configuring protection is to establish a session with the site (logging in, visiting the site or whatever actions are necessary to make the site issue a session cookie) and then view the cookies issued for that specific site in your browser.
- Finding session cookie name in Firefox
-
When a session is established view the cookie in ->+->->
Enter the domain name of the site in the search field.
| Session ID name
Input field |
The name of the cookie containing the session identifier. This field value is required to enable session and form (CSRF) protection.
|
| Secret for signing checksums
Input field |
A hard to guess string used to generate session cookie validation tokens.
|
| Idle session timeout
Input field |
Idle session timeout specifies the maximum duration of an idle session before it is dropped resulting in the user being logged out from the web site.
|
Cookie flags
| Add Secure flag to session cookie
Check box |
Add secure flag to session cookie to instruct users browser to only send the cookie over an SSL connection. Default: |
| Make session cookie HttpOnly
Check box |
Add HttpOnly flag to session cookie to instruct users browser to make the cookie inaccessible to client side script. Default: |
| Add SameSite flag to session cookie
Checkbox Drop-down option |
Add SameSite flag to session cookie for none, lax, or strict. Default: |
HSTS - HTTP Strict Transport Security
HSTS is a mechanism enabling web sites to declare themselves accessible only via secure connections - HTTPS. The policy is declared by web sites via the Strict-Transport-Security HTTP response header field. When enabling HSTS in WAF the Strict-Transport-Security header will be injected in server responses if it is not already present.
| Enable HSTS
Check box |
Add Strict-Transport-Security header to backend server responses if not already present. Default: |
| Max age
Check box |
Max age corresponds to the required "max-age" directive in the HSTS directive and specifies the number of days, after the reception of the STS header field, during which the User Agent (browser) regards the web server (from which the HSTS header was received) as a Known HSTS Host.. Default: |
| Enable session protection
Check box |
Enable / disable validation of session identifiers. If enabled, WAF will issue a validation cookie containing a cryptographic token (a checksum) which validates session id + client IP + secret for signing checksums (above) for each client request. The validation cookie is named __PFV__ and is issued whenever WAF detects a set_cookie with a cookie name matching the value configured (above) from the web site to protect. Default: |
| Session violation action
Check box |
What WAF should do when an invalid session id is detected. Session violation actions
Default: |
CSRF protection configuration
| Generate request form validation tokens (CSRF protection)
Check box |
Enable / disable generation of request form validation tokens (CSRF protection) If enabled, WAF will parse web system responses of type text/* searching for form tags. When forms tags are detected a session specific checksum validating the form action is inserted as a hidden parameter (named ___pffv___) to the form. Default: Now go to -> to enable request validation for specific applications (see Web application settings). If configured the Learner will learn and configure CSRF protection for applications. |
| Form violation action
Check box |
What WAF should do when an invalid request is detected. Form violation actions
Default: |
Request authorization configuration
| Enable request authorization
Check box |
Enable / disable request authorization for configured web applications. If enabled, WAF will authorize access to resources based on session validity. Request authorization is only enforced for resources for which this feature is enabled. Default: Now go to -> to enable request authorization for specific applications and other resources incl. static files (see Web application settings). |
Credential stuffing and brute force protection
Credential stuffing and brute force attacks are two of the most common methods cybercriminals use to compromise user accounts. Credential stuffing involves using stolen usernames and passwords to gain unauthorized access to systems, exploiting the fact that many users reuse credentials across platforms. Brute force attacks, on the other hand, rely on systematically trying numerous password combinations to break into accounts. Both attack types can lead to significant data breaches, financial loss, and reputational damage.
Behavioral tracking and CAPTCHA challenges
To detect and mitigate credential stuffing and brute force attacks, Fortra WAF employs a behavioral tracking mechanism on URL paths specified by regular expressions. By continuously monitoring traffic, the WAF establishes a dynamic baseline over a trailing one-week period, segmented with one-hour granularity. This approach enables the system to adapt to normal traffic fluctuations while remaining sensitive to unusual spikes that may indicate an attack.
When the traffic from a client - identified by IP address or netmask - exceeds a configurable threshold relative to the established baseline, the WAF issues a CAPTCHA challenge. This challenge serves as a verification step, requiring human interaction to proceed and effectively deterring automated attack attempts. Through this mechanism, the WAF limits the impact of malicious activity while maintaining access for legitimate users.
Once a source IP (or netmask) triggers a violation, based on tracking its activity on the protected pages, it will be required to complete a CAPTCHA to continue accessing the website serving the protected pages – regardless of what pages it requests.
Median Absolute Deviation (MAD) as a method for detecting abnormal traffic increases
Fortra WAF uses Median Absolute Deviation (MAD) for detecting abnormal increases in traffic load. MAD is a statistical approach for detecting unusual patterns by measuring typical variability around the median. It is especially useful in identifying anomalies due to its resilience to outliers.
To detect abnormal increases in traffic, multiples of MAD are used to set probability-based thresholds:
- 1 MAD typically captures about 50% of normal traffic variations.
- 2 MADs cover around 75%, marking moderately unusual traffic levels.
- 3 MADs capture over 90%, flagging highly unusual spikes.
These thresholds help identify the probability of a traffic spike being abnormal, with higher multiples indicating stronger anomalies. This adaptive approach enables consistent, probability-based detection of unusual traffic while accounting for normal fluctuations.
Configuring credentials stuffing and brute force protection
Credentials stuffing and Brute Force protection tracks activity targeting specific URL paths – typically login forms and other forms where attackers may try to guess secrets by repeatedly submitting the form.
Configuration includes:
- URL paths to track - Tracking and Enforcement
- Required increase in activity to trigger a violation - Activation threshold
- IP Precision – whether to track source IPs by netmask or the actual source IP
When the feature is enabled and configured, Fortra WAF will start baselining traffic patterns on the protected pages and mitigate Credentials Stuffing and Brute Forcing by issuing CAPTCHAs to clients triggering protection.
Tracking and enforcement
In this section, the pages to protect are defined. Note that activity is tracked on the protected pages but once activity exceeds thresholds protection is enforced everywhere on the protected website.
Each URL path is tracked individually with its own baseline. To prevent excessive resource consumption the number of URL paths that can be configured is therefore limited.
| URLs |
List of URL paths (protected pages) to track.
|
Activation threshold
The activation threshold defines the threshold for when the CAPTCHA service activates, and the HTTP client is required to solve the CAPTCHA to continue using the website.
The relative increases are based on Median Absolute Deviation (MAD) for the baseline profile for the protected page.
| Activation Threshold
Dropdown |
|
Source IP precision
Source IP Precision defines the unit that activity is tracked by, and controls are applied to - the scope of tracking.
Options range from “Off” – group all client source IPs, track activity on a general level, and apply CAPTCHA to all clients when surges are detected – to tracking source IPs individually.
If the Source IP precision option is set to Off, activity will be tracked as total requests per time slot. Activation of the control is based on a general surge in activity above an automatically calculated high water mark. When the activation threshold is exceeded, all clients are required to complete a challenge to be allowed access to the protected website. Tracking by a high water mark can be an advantage when an attack scenario involves credential stuffing or brute force attacks from many source IPs across different subnets, each making a few requests. Once the control is triggered, it applies to all clients. However, if the protected pages are processing many requests, there is a risk that tracking by a high water mark will allow a credential stuffing attack to "hide in the crowd." In the latter case, it may be better to trigger DDoS protection on general surges and set Source IP precision to a netmask (/24 - /32).
As both tracking and baselining are affected by the granularity of tracking, both will be reset when Source IP Precision changes.
| Source IP Precision
Drop-down |
|
Source status
When Credentials stuffing and Brute Force protection is enabled, source (as defined by Source IP Precision) activity is tracked on the protected pages (URL paths).
When a source triggers a violation by exceeding limits on the protected pages it is flagged as offensive and gets served a CAPTCHA regardless of what page on the protected website it requests next. Until the CAPTCHA is solved it won’t be able to reach the protected website.
Until the offensive status expires a new CAPTCHA will be served to the source IP tracking unit every time the CAPTCHA expires.
| Status Expiration
Input field |
Status expiration defines the time in minutes from the source IP tracking unit is flagged as offensive until that status is reset.
|
| Reset Status DB
Button |
Manually reset status DB. Will reset status for all offending sources. |
| Reset Tracking DB
Button |
Manually reset tracking DB. Will cause source tracking to restart data collection. |
Distributed denial-of-service protection
Fortra WAF leverages AWS or Azure DDoS mitigation capabilities to protect web applications deployed in AWS, Azure, on-premises, or in other cloud environments.
Key capabilities of AWS-based protection:
- Automatic provisioning of WAF rules to CloudFront and ALB
- JavaScript or CAPTCHA challenge-based validations for human traffic
- Dynamic IP allowlisting to restrict API access exclusively to verified clients during an attack
- Continuous traffic baselining and real-time anomaly detection
- Can also be configured for non-AWS based resources
Key capabilities of Azure-based protection:
- IP allowlisting to restrict API access exclusively to verified clients during an attack
- Continuous traffic baselining and real-time anomaly detection
- Only applicable to Azure based resources
See DDoS and Resource Attacks Mitigation in Fortra WAF for more information and recommendations for DDoS preparation and protection.
Global configuration
- Credentials: The credentials required to manage the cloud-based DDoS protection must be configured in System > Configuration.
- Resource ID: The identifier of CloudFront distribution, or application load balancer must be configured in Websites > Global Settings > Distributed Denial of Service protection.
AWS/Azure WAF
Enable automated baselining, attack detection, and mitigation.
| Enable DDoS protection
Check box |
Enable / disable traffic baselining and automated mitigation When enabled, Fortra WAF will baseline traffic patterns for a trailing 7 days with one-hour granularity and automatically enable cloud-based DDoS protection if traffic surges deviate substantially from the trailing baseline. Default: |
| Protection method
Drop-down |
Depending on the distribution of traffic patterns, as a rough measure, a multiple of 3 covers 90% of the baseline activity |
AWS JavaScript Challenge
The AWS WAF JavaScript Challenge is a bot mitigation feature that helps protect web applications by requiring browsers to execute a lightweight JavaScript snippet. If the script runs successfully, the request is allowed to proceed, confirming that the client is likely a real user rather than an automated bot.
Key Benefits (Pros)
- Effective against basic bots: Blocks bots that cannot execute JavaScript, such as simple scrapers or outdated automation tools.
- Seamless user experience: Operates silently in the background without requiring user interaction, unlike CAPTCHAs.
Limitations (Cons)
- Bypassable by advanced bots: Sophisticated bots that can execute JavaScript may still pass the challenge.
- Slight performance overhead: Adds a small delay to the request flow, which could impact page load times.
Billing and Pricing
- Per request charges: You are billed for each request that triggers the JavaScript Challenge.
- Rule evaluation fees: Standard AWS WAF rule evaluation costs apply.
For the most accurate and up-to-date pricing, visit the AWS WAF Pricing page.
AWS CAPTCHA
The AWS WAF CAPTCHA is a browser-based challenge that requires users to complete a visual test to prove they are human. It’s designed to block automated traffic by presenting a CAPTCHA when a request matches specific WAF rules. Only users who successfully complete the challenge are allowed to proceed.
Key Benefits (Pros)
- Strong bot defense: More effective than JavaScript challenges against advanced bots that can execute scripts.
- User verification: Provides a clear and visible test that confirms human presence.
Limitations (Cons)
- User friction: Requires user interaction, which can disrupt the user experience and lead to drop-offs.
- Accessibility concerns: May be difficult for users with visual or cognitive impairments.
- Localization issues: CAPTCHA content may not always be localized or culturally appropriate for all users.
Billing and Pricing
- Per CAPTCHA request: You are charged for each request that results in a CAPTCHA being served.
- Rule evaluation fees: Standard AWS WAF rule evaluation charges apply.
For the most accurate and up-to-date pricing, visit the AWS WAF Pricing page.
Known good IPs
This protection method involves restricting access to an API or application by allowing only a predefined list of trusted IP addresses. It is especially effective for APIs used by automated, recurring clients, such as backend systems, IoT devices, or partner integrations, where browser-based challenges like CAPTCHA or JavaScript execution are not feasible. By limiting access to these known good IPs, the system ensures that legitimate clients can continue to operate without interruption during DDoS attacks or other malicious traffic surges.
Key Benefits (Pros)
- Ideal for automated clients: Perfect for APIs where clients are non-interactive and cannot complete browser-based challenges.
- Ensures service availability: Keeps the API accessible to trusted clients during attacks by blocking all unknown or untrusted traffic.
- No client-side requirements: Eliminates the need for JavaScript or CAPTCHA support, making it suitable for headless or embedded systems.
- Low latency: Requests from trusted IPs are processed immediately, with no challenge-response overhead.
- Automated IP management: Fortra WAF dynamically learns and updates the list of known good IPs, reducing manual maintenance.
Limitations (Cons)
- Restricted access: New or dynamic clients must be added to the allowlist, which can delay onboarding or access.
- Risk of overblocking: Legitimate users may be denied access if their IPs are not included or if IPs change frequently.
- Not suitable for public APIs: Best used for private or partner-facing APIs, not for services with a broad or unpredictable user base where new clients will be denied access when under attack.
Billing and Pricing
- Standard AWS or Azure WAF charges: Uses IP set rules, which are billed under regular rule evaluation pricing.
- No challenge fees: Since no CAPTCHA or JavaScript challenge is issued, there are no additional per-request challenge costs.
Trusted clients - IP whitelisting
List if IP addresses which are trusted / whitelisted. The in- and output filters can be configured to be bypassed for the whitelisted addresses.
| Whitelist
Input field |
Per default, requests originating from any IP address (0.0.0.0/0) is affected when Pass Through Mode is enabled. The white list allows for the definition of specific IP address(es) or networks for which Pass Through Mode is enabled.
|
IP pass through
IP pass through allows for configuring overriding of filter actions based on the source of the request.
| Enable HTTP request blocking bypass for trusted clients
Check box |
Enable / disable HTTP pass through With Pass Through for trusted clients enabled, all requests will be forwarded to the real server, but will be otherwise handled the usual way (ie. WAF will learn about the site and log any would be blocked requests not matching the applied access control list). Default: |
| Enable IP network blocking bypass for trusted clients
Check box |
Enable / disable network blocking pass through When enabled, IP addresses listed as trusted clients will be included in the global list of IP addresses that are allowed to bypass network blocking and DoS mitigation controls. Note that the address will not be bypassed unless network blocking bypass is allowed in -> Default: |
Trusted domains
The trusted domains is a whitelist of domains which is composed of 1) the domain of the website proxy virtual host and the domains of the host names in Virtual host aliases and 2) a list of other trusted domains which can be entered manually.
The effective list of trusted domains is used in Remote File Inclusion signatures to leave out URLs targeting hosts within the list and when validating redirects to allow redirects to hosts within the list.
| Effective trusted domains |
This is the effective list of trusted domains, i.e. the automatically generated list of the domain of the website proxy virtual host, the domains of the host names in Virtual host aliases and the manually entered domains (if any). |
| Other trusted domains |
Enter additional domains to the list of trusted domains. Domains are separated by newline. |
| Include other trusted domains in domains list | When enabled the manually entered domains will be added to the effective trusted domains list. |
Evasion protection
| Block multiple and %u encoded requests
Check box |
Enable / disable blocking of multiple (or %u) encoded requests. In an attempt to evade detection attackers often try to encode requests multiple times. If enabled, WAF will block requests which after being decoded still contains encoded characters. Default: |
Duplicate parameter names
If duplicate parameter names are allowed, wrongly configured web application behavior may result in Alert Logic Managed Web Application Firewall (WAF) not learning the web site correctly and may also lead to WAF bypassing vulnerabilities depending on the target application/web server technology.
An attacker may submit a request to the web application with several parameters with the same name depending on the technology the web application may react in one of the following ways:
- It may only take the data from the first or the last occurrence of the duplicate parameter
- It may take the data from all the occurrences and concatenate them in a list or put them in an array
In the case of concatenation it will allow an attacker to distribute the payload of for instance an SQL injection attack across several duplicate parameters.
As an example ASP.NET concatenates duplicate parameters using ',' so /index.aspx?page=22&page=42 would result in the backend web application parsing the value of the 'page' parameter as page=22,42 while WAF
may see it as two parameters with values 22 and 42.
This behavior allows the attacker to distribute an SQL injection attack across the three parameters.
/index.aspx?page='select data&page=1 from table would result in the backend web application parsing the value of the 'page' parameter as 'select data, 1 from table while
WAF may see it as two parameters with values 'select data and 1 from table.
By default, when WAF validates parameters negatively it automatically concatenates the payload of duplicate parameters. It is mostly in the case where a positive application or global rule allows a specific parameter with an input validation rule that makes room for attacks like the above the parameter duplication problem exists. In the page example above the attack would be stopped because the page parameter would be learned as numeric input (an integer). This would not allow text input like in the example above. Nevertheless it is important to configure WAF to mimic the target web applications parsing of requests as closely as possible.
| Block duplicate parameter names
Check box |
Enable / disable blocking of duplicate parameter names. If enabled, WAF blocks requests containing duplicate parameter names. Default: |
| Join duplicate parameter names
Check box |
Enable / disable concatenation duplicate parameters. If enabled, WAF will concatenate the values of the duplicate parameters using the configured join separator (below). Default: |
| Join separator
Input field |
Character(s) used for separating concatenated parameter values.
|
The best option is to disallow duplicate parameter names. It may not be practical though as the use of duplicate parameters
may be intended in some applications - the most prominent example being PHP which parses parameter names suffixed with [] as an array - like par1[]=22&par1[]=42 becoming array(22,42). If this feature is not in use block it.
If the application technology is ASP/IIS or ASP.NET/IIS and it is not possible to disallow duplicate parameters the recommended setting is to join duplicate parameters using ',' as in the join separator example above.
Path resolution normalization
Normalize URL path for web application policy rules lookup by
- Collapsing consecutive slashes
- Trimming directory path – like replacing
somedir/../with/ - Replacing trailing
/.With/ - Replacing
/./with/
Normalization does not apply to validation of the URL path itself.
Time restricted access
Access to a website can be restricted on a time basis.
For each weekday enter opening hours.
| Opens
Input field |
Time the website opens on the weekday.
|
| Closes
Input field |
Time the website closes on the weekday.
|
To specify dates where the website is closed enter a list of dates in the format mm/dd separated by whitespace, comma or semicolon.
Input validation classes
Characters classes are useful when you want to use a predeclared set of criteria used by WAF for input request validation. Eg. if you have lots of HTML forms that use an input field "email", you can define a class and a regular expression which defines what a valid e-mail address is. This class can then be used throughout the entire policy.
When a class is changed, all affected policy elements are automatically updated to reflect the change.
| Rank
Read only |
The class rank when used by the Learner. To change the rank, place the cursor in one of the classes input fields. The rank number will be indented. Use the buttons and in the lower button panel to change the class' rank. |
| Name
Input field |
The class' name.
|
| Value
Input field |
The class regular expression.
|
| X
Button |
Mark class for deletion. When classes are saved the marked classes will be deleted. When deleting classes that are in use in the policy you will be prompted to accept replacement of the deleted classes with existing classes. Learner data samples using deleted classes will be deleted. |
For more information about classes and their corresponding regular expressions, refer to Regular expressions.
Some user input is so complex and unpredictable that, to avoid false positives, positive validation of input ends up being very general and loose. An example of this is free text input fields which often get mapped to the input validation class "printable" which basically allows all printable characters. It is often better validate such input negatively - which WAF does by default.
WAF determines if an input should be validated negatively based on the input validation class rank. By default
the threshold is the class Printable. If a parameters input is learned/configured to be the class configured as threshold the signatures policy will be used instead
of the class regular expression.
| Move up |
Change the rank of the selected class. To move the class upwards. Select the class by clicking anywhere in the class row. When selected the class rank number is highlighted and indented. Click Move up to move the class one step upwards. |
| Move down |
Change the rank of the selected class. Works as described above. |
| Add new | Add new class. When clicked an empty row will appear at the bottom of the class list. Fill out the blanks and place the class in the class hierarchy with the move buttons. |
| Policy type
Drop-down |
The policy type can be either API or WAF. Changing the policy type has no direct impact but determines the default classes that are loaded when selecting Load Defaults. While the WAF policy type input validation classes are fewer and more tailored towards a website with user input, the API policy type input validation classes are more directly mapped to the specific OpenAPI Data Types and Formats |
| Signature validation above
Drop-down |
The class rank above and including which input will be validated negatively.
To disable negative class checking select |
Web application validation order
To prevent unintended rule matches from overlapping URL path regular expressions, the order in which web application policy rules are selected based on request URL paths can be defined.
When validating a request more specific policy scopes take precedence over less specific. Rules defined in a web application rule only apply to the URL path that is key to the rule and are thus a more specific scope than global rules that apply to all requests.
Web application rules are selected based on the URL path, but since the selection is based on a regular expression the scope of web application rules can be more or less specific and possibly overlapping, as evident from these examples (full match - ^[path regex]$ - is implied):
.+\.php: Matches all URL paths with extension.php/shop/payment\.php: Only matches the URL path/shop/payment.php
To prevent the more general URL path regular expression from matching requests for /shop/payment.php the order of the examples above should be changed to:
/shop/payment\.php: Only matches the URL path/shop/payment.php.+\.php: Matches all URL paths with extension.php
Changing the order of validation
- In the list of URL path regular expressions, select the URL path to move by clicking on it.
- Press the buttons Move Up or Move Down to change its position in the list.
- Repeat for other URL paths as required.
- Click Save and apply changes.
Bot and client automation management
Bot and client automation management establishes a set of rules for acting on requests matching a pre-classified database of well-known bots and well-known automated clients or, alternatively, unknown user agents and applying several possible controls to the request.
An initial set of rules appears by default, and the groups of bots and automated clients they manage are labeled in the Description field:
| Bots - falsified user agent |
Distrust and logs or block activity from bots that impersonate as other - possibly more trustworthy - bots |
| Unknown user agent |
Distrust activity from unknown user agents and verify that a human is driving the session by issuing a CAPTCHA |
| Bots - known web scraper |
Distrust and log or block activity from bots that are known web-scrapers |
| Hacking tools | Distrust activity from known hacking tools – engage trust-based controls, including erring on the side of detection and engage more sensitive signatures |
| Client user agents - scriptable | Distrust activity from scriptable user |
| Client tools - automated | Distrust activity from automated user |
| Bots - no verification data | Distrust bots that do not provide means of verification - or where source IPs are not otherwise known |
| Bots - known source IP | Allow and trust bots where claimed identity matches source |
| Unknown user agent | Distrust activity from unknown user agents and verify that a human is driving the session by issuing a CAPTCHA |
Adding a new rule defines a group of bots or automated clients based on their general characteristics and defines the controls applied to the new grouping.
Identification and verification of clients
Identification of bots, scriptable user agents, browsers, and other human driven user agents like email clients is based on the user agent set in the request. This is the claimed identity which is then verified based on available means of verification such actually-detected automation behavior (vs expected capability) and source IPs, reverse DNS, or ASN lookup for bots.
When the client session is identified and possibly verified it is classified as either “bot” or “client” and attributes characterizing the session are set.
Evaluation order
Rules are evaluated in the order they are listed in the rules table and the first rule that matches the combined attributes is applied. First match wins.
As rules can potentially be overlapping, evaluation order should follow specificity of attributes with the more specific rues at the top. As an example, the rules allowing verified bots in general are overlapping and conflict with the rule disallowing web scrapers as it is very likely that web scraper bots can be weakly or strongly verified. The web scraper rule is therefore evaluated before the rules allowing verified bots.
Applying controls
Controls are applied to the session identified by the source IP based on the characteristics/attributes set for the session. The assigned session attributes and controls that can be applied are described in the table below.
| Rank |
Order rules are evaluated in |
| Status |
Turn the rule on or off |
| UA |
Attribute - User-Agent classification:
|
| Classification |
Attribute - Functional classification. Options are different for bot and client. Options for bot type:
Options for client type:
|
| UA Auto Capability |
Attribute - User-agent automation capability:
|
| Description | Text field describing the target of a rule |
| Verification |
Attribute - Outcome of verification of bot user agent
|
| Violation |
Control - Violation type to apply - determines action as configured in WAF Operating Mode Definitions
|
| Trust |
Control - Trust score to apply - determines factors like Adaptive Protect Mode and sensitivity of signatures applied to requests from source IP
|
| Challenge |
Control - Challenge to apply - intended for bots and automated clients claiming to be human-driven user agents
|
| Source class |
Assign connections matching the rule to an IP Source Class to be able to be able to apply control group controls by bot classification.
As an example, the Good Bots Source Class can be used for valuable search engine crawlers to assign a Req Throttle zone that allows for fast crawling, Acceptable Bots could be used for bots providing less obvious value to limit their resource usage by assigning a Req Throttle zone that allows for lower request rate, and Bad Bots could be used for blocking the requests by assigning a Blacklisting violation or throwing a Challenge. |
User agent report
The user agent report shows configured rules applied to known bots and user agents.
The report can be filtered by adding filter criteria in the row beneath the heading row. Filters are regular expressions but do not have to be enclosed in “/”.
See the filter examples below:
| Show all scriptable user agents |
Automation = script |
| Show all scriptable user agents of type library |
Automation = scriptable Classification = library |
| Show all scriptable user agents of type library or feed_reader |
Automation = scriptable Classification = library|feed_reader |
| Show all user agents in web scraper family "cf-uc_user_agent" |
Family = cf-uc "Show unique only" option = unchecked |
To filter the report, click the Apply Filter button.
Show unique only
For bots in particular, the same bot with the same fundamental attributes can be represented by different user agents and associated bot names without the “family name” and bot classification changing.
As rules are applied to bot classification attributes a rule that matches one version of a bot also applies to all other versions of that bot. The list is therefore grouped by bot attributes to only show unique samples of how bot rules are applied. To show all versions of a user agent uncheck the option “Show unique only”. A use case for this could be to filter by a specific bot family to see all the user agents in that family.
L7 Source IP and Geolocation based controls
As a two-step procedure, L7 Source IP and Geolocation based controls define how to map facts about connections to the WAF to different ways those connections can be managed.
As a first step, facts about connections to the WAF ("Source Classes") are mapped to Control Groups. Then, Control Groups are mapped to the ways those connections can be managed ("Violation," "Trust," and "Challenge").
Module status
By default, the module for L7 Source IP and Geolocation based controls is disabled. The module can be enabled by changing Module status from Inactive to Active. Proceed to select Save and then confirm the configuration change by selecting apply changes.
Source classes
Source Classes are groups of source IPs. Source Classes each represent facts about connections to the WAF such as country of origin, passing through an anonymizing proxy like TOR, or past or current observed hostile or anomalous behavior.
Source Class configuration is organized in a table with an expandable section containing unconfigured GeoIP country groups:
Name: Name of the Source Class.
Group: A Control Group is assigned to each Source Class. The Control Group is selected in the Group column in the Source Classes configuration table.
Effective Group: Source Classes not specifically assigned a Control Group will be assigned the Control Group designated as the Default. For each Source Class this is shown in the column Effective Group.
Default Source Class configuration
| Class Name | Group | Effective Group |
|
TOR Exit Nodes IP addresses recently determined to be TOR Exit Nodes |
Dubious Sources | Dubious Sources |
|
Fortra Threat Intelligence Blacklist IP addresses recently identified with high confidence as bad actors by Fortra Threat Brain |
Blacklisted | Blacklisted |
|
Anomalous Session IPs IP addresses with recent session behavior determined to be anomalous for this website (see Session Anomaly Detection, below) |
Dubious Clients | Dubious Clients |
|
RFC1918 private IP addresses Private IP addresses by design not associated with a country code |
Default | No Controls |
|
Unconfigured GeoIP IP addresses not associated with a country code |
Default | No Controls |
|
Country Country of origin. The country classes are Hidden until "Show Unconfigured GeoIP* Sources" is clicked |
Default | No Controls |
*The country source classes are based on GeoLite2 data created by MaxMind, available from https://www.maxmind.com.
Control Groups
Control Groups each represent a set of ways to treat connections to the WAF. The controls/actions applied to a source IP depend on the Source Class(es) it belongs to.
Violation: Violation determines whether requests that belong to the Control Group will be treated as Violations.
Violation options are None and Blacklisted. When Blacklisted is selected the action configured for that violation is applied to the request.
Violation action is by default Block when in Protect Mode and Log (but do not block) when in Detect Mode. Violation action is configured in “WAF operating mode definitions” in the “Basic operation” section of the Policy configuration page.
Trust: Trust determines whether requests that belong to the Control Group will be treated with lower confidence that the source is benign, for example subjecting them to additional assessment such as applying lower confidence signatures. Note that acting on Trust in this way is a feature of the advanced signature engine, enabled for each website in the “Website global policy” section under “Attack signatures usage.”
Challenge: Challenge determines whether requests that belong to the Control Group will be presented with a CAPTCHA.
Reg Throttle: Assign an HTTP request throttling zone to control request rate.
Default: The Control Group selected as the Default will be applied to all requests from source IPs that belong to an unconfigured Source Class group.
Default Control Group configuration
| Group | Violation | Trust | Challenge | Default |
| No Controls | None | No downgrade | None | * |
| Blacklisted | Blacklisted | Low | None | |
|
Dubious Sources Intended to be used for Source Classes that are considered questionable regardless of detected activity. As an example, TOR exit nodes are assigned to this group. |
None | No downgrade | CAPTCHA | |
|
Dubious Clients Intended to be used for Anomalous Session IPs - clients that behave differently and have capabilities that are different from what the User-Agent header would suggest. Also, clients that “lie” about their User-Agent – like a bot claiming to be a big search engine but does not validate as such. |
None | No downgrade | CAPTCHA |
Whitelisting vs Blacklisting source IPs / countries
Changing the default Control Group to Blacklisted offers a means of blocking all traffic by default while allowing only specific Control Groups access to the WAF. For example, setting the default to Blacklisted will block all traffic by default, and then, setting the Control Groups for specific country codes to No Controls will allow access for IPs associated with a specific list of country codes.
Show/Hide Unconfigured GeoIP sources toggles a list of countries, each configurable as a Source Class.
Multiple Control Group associations
A source IP may be or become associated with multiple Source Classes. For example, it might be a Tor Exit Node associated with the Dubious Sources Control Group and later get added to the Fortra Threat Intelligence Blacklist associated with the Blacklisted Control Group. In cases where more than one Control Group apply, the strictest of each of the controls from each group will be applied.
In the example case where both Dubious Sources and Blacklisted apply and, with the configuration above, the combination of controls applied will be:
- Violation: Blacklisted (Blacklisted: Blacklisted, Dubious Sources: None)
- Trust: Low (Blacklisted: Low, Dubious Sources: None)
- Challenge: CAPTCHA (Blacklisted: None, Dubious Sources: CAPTCHA)
Trusted Proxy / X-Forwarded-For
It is common for websites to be deployed behind one or more reverse proxies – such as CDNs and Layer 7 load balancers. In fact, the WAF is a reverse proxy itself.
When a request passes through proxy servers, each server adds the respective source IP to the X-Forwarded-For (XFF for short) request header. The XFF header then contains a list of IP addresses the request has passed through. When arriving at the WAF the source IP of the request will be a reverse proxy and the original source IP, the IP the controls should be applied to, will be in the XFF header.
As the XFF header can be forged by a malicious agent, extracting the correct client source IP from the XFF header is based on the concept of “trusted proxies.”
While only proxy servers are supposed to write to the XFF header, as the header is a list that every proxy server it passes through writes to, a client can include an XFF header in the initial request with false IPs. Therefore, only parts of the XFF header IP list can be trusted, namely the IP addresses that were inserted by proxy servers the client making the request cannot be expected to control. Such proxy servers are denoted “Trusted Proxies” in the context of this WAF.
If Trusted Proxy / X-Forwarded-For source IP extraction is not configured or enabled, a warning that there is a risk of applying controls to the wrong source IPs will be displayed.
Session anomaly detection
Session anomaly detection is a feature that groups user requests into sessions and uses machine learning to create models that represent a website's typical traffic patterns. These models are then utilized to predict if a future session is anomalous or not.
By default, session anomaly detection is disabled. A user can activate this feature by changing Module status from Inactive to Active Proceed to select Save and then confirm the configuration change by selecting apply changes.
To determine whether a given session is anomalous or not, a machine learning algorithm is utilized. This evaluation is based on a set of features used to calculate a session "score". The score is then compared against a trained model to determine if the session is anomalous.
The session's features include HTTP methods, status codes, the types of resources being requested (e.g., images, JS, HTML, PDF, and dynamic resources like PHP or ASPX), the existence of a Referer header, and whether /robots.txt was requested.
Model status table
| Model |
Currently, two models are constructed for sessions: bot and client. A session is trained or predicted based on the user-agent header extracted from requests. |
| Learning progress |
The current percentage of sessions that have been collected to meet model training requirements. |
| Anomalies | The count of anomalous sessions that have been predicted (detected). |
| State |
A model is either in a Training or Predict (detect) state. Predictions for anomalies cannot occur until a model has been fully trained. |
| Last modified | The date and time that a model completed training. |
| Filesize on disk (bytes) | The size of the serialized model on disk. |
Detection sensitivity slider
The detection sensitivity slider allows users to adjust the threshold used to determine whether a session is anomalous or not. By sliding the control to the left, the sensitivity is decreased, resulting in fewer anomalies being detected. Conversely, sliding the control to the right increases the sensitivity and should detect more anomalies.
Increasing sensitivity effectively “lowers the bar” for when a session is considered anomalous and, consequently, also increases the risk of the model generating false positive anomalies. Conversely, lowering sensitivity raises the bar but also decreases the risk of false positives.
It is recommended to leave the slider in the default position for optimal performance.
Detected anomalies
When a session is detected as anomalous the observation is logged and client source IP is flagged as an Anomalous Session IP which can be managed in “L7 Source IP and Geolocation based controls” where different controls – like blocking, CAPTCHA challenge, and lowering connection trust can be applied to the source IP.
Load defaults
The "Load Defaults" button enables users to reset the current session anomaly detection models. Selecting "Load Defaults" erases any existing configurations, replaces them with the original default settings, and deletes any trained models. Additionally, the module status is set back to "Inactive".
Note that this action is permanent and cannot be undone, so take caution when selecting this option.
Normally it is not necessary to reset learning but if, for instance, website usage patterns change or substantial changes are made to the website and lots of redirects are sent to accommodate Google it may be necessary to reset the learning model.
CAPTCHA challenge
CAPTCHA challenges are an effective way to control access from automated clients to the protected web application.
CAPTCHA challenges are typically served in response to suspected automation as configured in Bot and client automation management or to mitigate a brute force attempt as configured in Credential stuffing and brute force protection.
CAPTCHA challenge configuration applies to challenges served or injected by the WAF, not those served when DDoS protection is pushed into the cloud.
Configuration Options:
- CAPTCHA Challenge Served by the WAF: A standard CAPTCHA text image recognition challenge provided directly by the WAF.
- Google reCAPTCHA v2 Checkbox: Integrates Google reCAPTCHA v2 for a checkbox-based challenge.
- hCaptcha Checkbox: Utilizes hCaptcha for a checkbox-based challenge.
Third-Party CAPTCHA Credentials
For Google reCAPTCHA and hCaptcha, third-party CAPTCHA credentials must be configured in System > Configuration.
Fortra Web Application Firewall (WAF) API Protection
The Fortra WAF provides robust protection for APIs by parsing OpenAPI definitions and creating policy rules for each endpoint. These rules are specific to the endpoint paths and support extracting values from named URL path parameters (e.g., /api/pets/{id}).
How it works
- Parsing OpenAPI Definitions: The WAF parses the provided OpenAPI definition to understand the structure and endpoints of the API.
- Creating Policy Rules: For each endpoint in the OpenAPI definition, the WAF creates positive policy rules to allow the HTTP methods defined in the OpenAPI specification.
- Input Validation: The WAF maps each endpoint's input parameters to an input validation class based on the OpenAPI data type and format.
- Policy Type: Input Validation Class mapping is dependent on policy type. While the WAF policy type input validation classes are fewer and more tailored towards a website with user input, the API policy type input validation classes are more directly mapped to the specific OpenAPI Data Types and Formats.
Input validation classes
Input validation classes are a collection of predefined named regular expressions used for positive policy rules. When changing a class, all policy rules using that class will be affected. Classes are ordered (ranked) by specificity, indicating how complex the input the class allows.
For each endpoint definition, parameters will be mapped to input validation classes based on their data type and format. For example, a parameter with the type string and format byte will be mapped to the string_byte validation class.
Classes with complexity above a configurable threshold (defined by class rank) can have signature validation added to the class-based validation. This is configured in the Input Validation Classes section of the WAF policy page. For the API policy type, the default is to add signature validation for the class string_printable ([^\x00-\x08\x0b\x0c\x0e-\x1f\x7f]+).
Policy type
The policy type can be either API or WAF. The policy type determines the default classes and how they map to OpenAPI data types. The API policy type is recommended for API protection because the default class definitions are different between the two policy types.
The policy type can be set in:
- Policy > Website Global Policy > Input Validation Classes
- By applying the WAAP_Defaults template
- By selecting the WAAP website type when a new website is created
It is recommend to separate API protection from the protection of a website with user interaction because of the difference in class definitions. If it is not possible to separate the two, then the API policy type is recommended for new website / API configurations because of a clearer mapping to OpenAPI data types.
When the API is served from the same domain name as a “conventional” user-facing website where the WAF policy is already tuned, it is not recommended to change the policy type to use API specific input validation classes as this will interfere with policy rules that are using existing WAF Type classes. Instead, the class mapping and possibly the class definitions should be modified to strike an acceptable balance between the existing policy and API validation.
API Definitions Management
The WAF UI provides a section for managing API definitions:
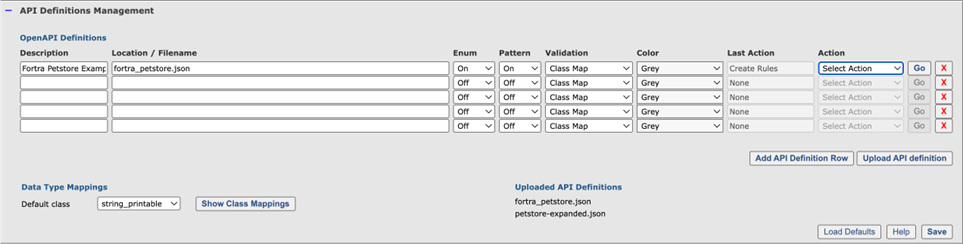
OpenAPI definitions
The OpenAPI definitions table enables bulk management of API definitions. Each row in the table represents an API definition, and you can use the Action drop-down menu to manage rules for the API.
API definitions can be uploaded to the WAF or, if a URL is provided, read from a remote location.
The fields in the OpenAPI Definitions table are:
- Name: The name of the OpenAPI definition (e.g., petstore).
- Location / Filename: The URL or name of the OpenAPI definition (e.g., petstore-expanded.json) as listed in the Uploaded API Definitions section.
- Enum: Create static validation rules for parameters with the enum property set. An enum property is a list of static values that are allowed as input.
- Pattern: When present, use input validation pattern definitions in the API specification to validate request parameter values.
- Validation: Class-based validation of OpenAPI data types and formats.
- Class Map: Map OpenAPI data types and formats to Input Validation Classes as defined in the Data Type Mappings section.
- Default Class: Use Default Class for all input as defined in Data Type Mappings.
- Color: Select which color the endpoint rules resulting from API definition should be coded with. This allows for distinguishing between endpoints from different API definitions in the list of endpoint policy rules.
- Last Action: Last action performed on the API definition.
- Action: Once the API definition is saved, you can manage it by selecting actions in the Action drop-down and then executing them by clicking the corresponding Go button.
- Test Import: Perform a dry run on creating policy rules from the API definition. This will show if the API definition parses correctly.
- Create Rules: Create policy rules from the API definition. The rules will be created in a disabled state to allow for adjustments before enforcing them.
- Enable / Disable Rules: Toggle enabling or disabling the endpoint rules associated with the API definition.
- Delete Rules: Delete all rules created from the API definition. You can recreate rules by selecting Create Rules.
Violations supported
JSON-based OpenAPI v3 definitions are supported.
Data type mappings
The WAF allows you to map OpenAPI basic types and formats to specific validation classes. The default mappings are shown below for API and WAF policy type (may vary slightly depending on WAF version).
You can change each mapping by selecting the drop-down menu in the WAF Input Validation Class field.
API Policy Type mappings
The API Policy Type input validation classes are tailored for and directly mapped to the OpenAPI data types and formats and require little or no adjustment of the mappings:
| API Data Type | API Data Type Format | WAF Input Validation Class | Signature Validation |
| array | default | string_printable | On |
| boolean | default | Boolean | Off |
| integer | default | Integer | Off |
| integer | int32 | Integer | Off |
| integer | int64 | Integer64 | Off |
| number | default | number | Off |
| number | double | number | Off |
| number | float | number | Off |
| object | default | string_printable | On |
| string | binary | string_binary | On |
| string | byte | string_byte | Off |
| string | cidr | string_cidr | Off |
| string | date | string_date | Off |
| string | date-time | string_date-time | Off |
| string | default | string_printable | On |
| string | string_email | Off | |
| string | hostname | string_hostname | Off |
| string | ipv4 | string_ipv4 | Off |
| string | ipv6 | string_ipv6 | Off |
| string | password | string_printable | On |
| string | uri | string_uri | Off |
| string | uuid | Uuid | Off |
WAF Policy Type mappings
When the API is served from the same domain name as a “conventional” user-facing website where the WAF policy is already tuned, it is not recommended to change the policy type to use API specific input validation classes as this will interfere with policy rules that are using existing WAF Type classes.
In this case, it is necessary to adjust the mappings to balance API input validation with existing class usage – possibly with small changes to class definitions as required, like changing the num input validation class from \d{1,32} to [+-]?\d{1,64}.
The mapping recommendations in the table below provide a good starting point. Note that the Signature Validation is read only as it is defined in the Input Validation Classes section of the policy. The Signature Validation field is not updated until the new class mappings are saved.
The recommended mappings below must be configured manually. Once configured, the mappings apply to all imported API definitions.
| API Data Type | API Data Type Format | WAF Input Validation Class | Signature Validation |
| array | default | printable | On |
| boolean | default | alphanum | Off |
| integer | default | num | Off |
| integer | int32 | num | Off |
| integer | int64 | num | Off |
| number | default | text | Off |
| number | double | text | Off |
| number | float | text | Off |
| object | default | printable | On |
| string | binary | anything_multiline | Off |
| string | byte | base64 | Off |
| string | cidr | text | On |
| string | date | text | Off |
| string | date-time | text | Off |
| string | default | printable | Off |
| string | text | Off | |
| string | hostname | text | Off |
| string | ipv4 | text | Off |
| string | ipv6 | text | Off |
| string | password | printable | On |
| string | uri | url | Off |
| string | uuid | ms_ident | Off |
Resulting endpoint policy rules
Rules created from an OpenAPI definition are of type API Path Definition. This type differs from the Web Application policy rule type in that the URL path is parsed differently. While the Web Application policy rule path is defined as a regular expression, the API Path Definition is following the OpenAPI path definition syntax that allows for path-based parameters.
Path-based parameters
Path-based parameters are dynamic parts of the URL path that capture specific values. For example, in the endpoint /api/pets/{id}, {id} is a path-based parameter that can capture the value of a pet's ID.
Fortra WAF creates a policy rule for each path-based parameter in the endpoint policy rule. In the case of /api/pets/{id}, the WAF will create a policy rule identified by its OpenAPi path - /api/pets/{id} - and a specific rule for the input parameter id to handle the validation and extraction of the value from the URL path.
Creating protection from an API definition
To create protection from an API definition, follow these steps to ensure your API is properly managed and secured within the WAF interface. This process involves uploading the API definition, configuring its settings, and managing the rules associated with it:
- Navigate to the API Definitions Management section in the WAF GUI.
- Click Upload API Definition, and then select the OpenAPI definition file to upload.
- In the API Definitions Table, add the following API definitions:
- In the Description box, enter a name for the API definition (e.g., Petstore API).
- In the Location / Filename box, select the uploaded API definition file from the drop-down menu. Alternatively, enter a URL if the API definition is located on an external server.
- In the Validation drop-down menu, select the validation type.
- Class Map will map API definition data types to WAF validation classes (recommended).
- Default Class will map all inputs to the default validation class.
- In the Color drop-down menu, select the color coding for the API endpoints. This is useful when endpoints from multiple API definitions are served from the same domain name.
- The Action drop-down menu will appear dimmed until the new API settings are saved.
- Click Save. The Action drop-down menu will become enabled.
- In the Action drop-down menu, select one of the following actions and then click Go to execute it:
- Test Import: Performs a dry run on creating policy rules from the API definition. This will show if the API definition parses correctly.
- Create Rules: Creates policy rules from the API definition. The rules will be created in a disabled state to allow for adjustments before enforcing them.
- Enable / Disable Rules: Enables or disables the endpoint rules associated with the API definition.
- Delete Rules: Deletes all rules created from the API definition. Rules can be recreated by selecting Create Rules.
- Click Save.
When creating rules, it may be necessary to adjust endpoints to accommodate factors such as limitations on request body size for large upload requests. In such cases, switching to streaming body inspection might be required.
When enabling rules, consider either putting the policy or individual endpoint rules in Detect (log only) mode to validate everything is working as expected before switching to Protect mode.
Resulting policy
Importing and creating rules for the Fortra Petstore Example API definition will result in three OpenAPI endpoint rules.

The rules are created in a disabled state and until enabled they are not effective. When enabled the color of the URL path changes in the list.

Basic concepts
The /v1/pets/{petId} rule illustrates some basic concepts.
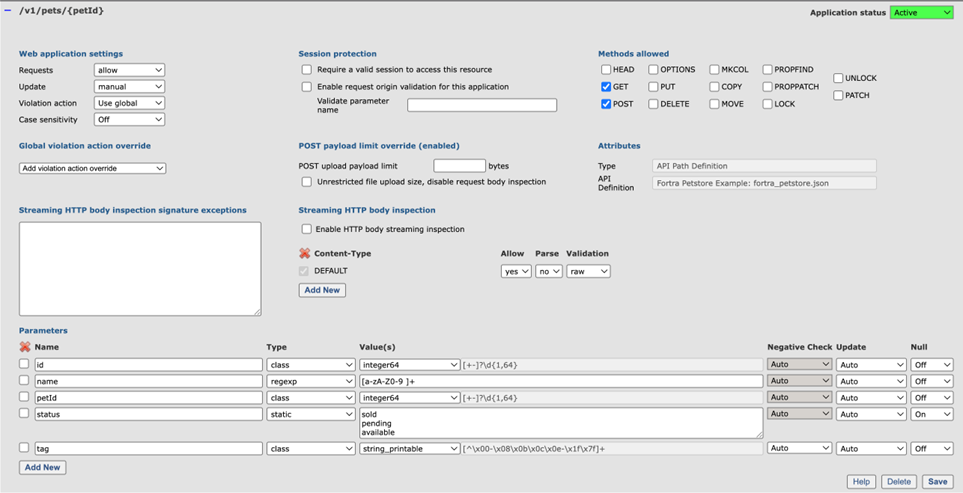
Path based parameters – The parameter named petId is in the URL path – the {petId} part. The value is extracted from the URL path. As an example, the petId value in the URL path /v1/pets/42 will become 42.
Pattern – The parameter name has a pattern property in the API definition. The resulting validation rule is of type regex and using the validation from the definition.
Enum – The parameter status has an enum property in the API definition. The resulting validation rule is of type static and using the list of static values in the definition.
Class-based validation – Parameters id and petId have type (integer) and format (int64) properties in the API definition. Integer/int64 is mapped to the WAF input validation class integer64 ( [+-]?\d{1,64} ) as shown in the list.
Methods allowed – The API path has specifications for both GET and POST methods so both methods are allowed. All other methods are disallowed.
Streaming inspection – When the requestBody definition of an API path specifies a content type that the WAF does not parse, streaming inspection is automatically enabled for all specified content types for that specific API path.
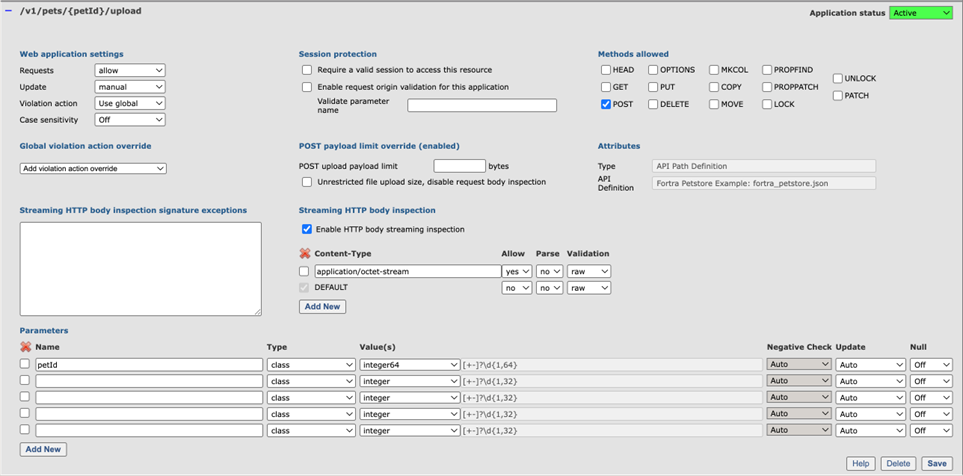
In the case of the /v1/pets/{petId}/upload rule, the requestBody has specifications for the application/octet-stream content type. This content type is not parsed by Fortra WAF so streaming HTTP body inspection with inspection of the unparsed request body is enabled for that specific API path. As a result, signatures suitable for inspection of raw data are used to validate the request body data while it is streamed to the protected backend.
DEFAULT is set to Allow=no, meaning any content type, but application/octet-stream is disallowed and will be blocked.
Streaming inspection allows for inspecting request bodies of unlimited size.
Open API
API definition formats
Fortra WAF supports OpenAPI version 3 definitions, which allows for a wide range of API specifications to be used for creating protection rules. Since Swagger is the original name for OpenAPI, any Swagger definitions already in the OpenAPI format can be used directly with the Fortra WAF.
Additionally, API definitions in other formats can be converted to OpenAPI format using various tools and services. Examples include:
- Postman Collections
- RAML (RESTful API Modeling Language)
- API Blueprint
- WSDL (Web Services Description Language)
Tools like API Transformer and API Spec Converter can be used to convert these formats to OpenAPI.
OpenAPI API definition format
The OpenAPI Specification (OAS) defines a standard, language-agnostic interface to HTTP APIs, allowing both humans and computers to discover and understand the capabilities of the service without access to source code, documentation, or network traffic inspection. An OpenAPI definition is a document that describes the surface of an API and its operations in a machine-readable format. It can be written in either JSON or YAML. Fortra WAF supports JSON, and YAML can easily be converted to JSON if needed.
Key components of an OpenAPI definition
- OpenAPI Object: Specifies the version of the OpenAPI Specification being used.
- Info Object: Provides metadata about the API, such as the title, version, and description.
- Paths Object: Lists the available API endpoints and the operations that can be performed on each endpoint.
- Components Object: Defines reusable schemas, parameters, responses, and other components.
- Security Object: Specifies the security mechanisms that can be used across the API.
- Tags Object: Allows for logical grouping of operations by resources or any other qualifier.
- External Documentation Object: Provides additional external documentation references.
Example of an OpenAPI definition (JSON)
The following example is a modified version of the petstore.json API definition used on OpenAPI and Swagger websites to demonstrate OpenAPI capabilities.
{
"openapi": "3.0.0",
"info": {
"title": "Fortra Petstore Example",
"description": "A sample API to illustrate OpenAPI concepts",
"version": "1.0.0",
"license": {
"name": "MIT"
}
},
"servers": [
{
"url": "http://petstore.swagger.io/v1",
"description": "Main (production) server"
}
],
"paths": {
"/pets": {
"get": {
"summary": "List all pets",
"operationId": "listPets",
"tags": [
"pets"
],
"parameters": [
{
"name": "limit",
"in": "query",
"description": "How many items to return at one time (max 100)",
"required": false,
"schema": {
"type": "integer",
"maximum": 100,
"format": "int32"
}
}
],
"responses": {
"200": {
"description": "A paged array of pets",
"headers": {
"x-next": {
"description": "A link to the next page of responses",
"schema": {
"type": "string"
}
}
},
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/Pets"
}
}
}
},
"default": {
"description": "unexpected error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/Error"
}
}
}
}
}
},
"post": {
"summary": "Create a pet",
"operationId": "createPets",
"tags": [
"pets"
],
"requestBody": {
"description": "Pet object that needs to be added to the store",
"required": true,
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/Pet"
}
}
}
},
"responses": {
"201": {
"description": "Null response"
},
"default": {
"description": "unexpected error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/Error"
}
}
}
}
}
}
},
"/pets/{petId}": {
"get": {
"summary": "Info for a specific pet",
"operationId": "showPetById",
"tags": [
"pets"
],
"parameters": [
{
"name": "petId",
"in": "path",
"required": true,
"description": "The id of the pet to retrieve",
"schema": {
"type": "integer",
"format": "int64"
}
}
],
"responses": {
"200": {
"description": "Expected response to a valid request",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/Pet"
}
}
}
},
"default": {
"description": "unexpected error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/Error"
}
}
}
}
}
},
"post": {
"summary": "Update a pet",
"operationId": "updatePet",
"tags": [
"pets"
],
"parameters": [
{
"name": "petId",
"in": "path",
"required": true,
"description": "The id of the pet to update",
"schema": {
"type": "integer",
"format": "int64"
}
}
],
"requestBody": {
"description": "Pet object that needs to be updated",
"required": true,
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/Pet"
}
}
}
},
"responses": {
"200": {
"description": "Pet updated successfully",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/Pet"
}
}
}
}
}
}
},
"/pets/{petId}/upload": {
"post": {
"summary": "Upload pet documentation and pictures",
"operationId": "uploadPetFiles",
"tags": [
"pets"
],
"parameters": [
{
"name": "petId",
"in": "path",
"required": true,
"description": "The id of the pet to upload files for",
"schema": {
"type": "integer",
"format": "int64"
}
}
],
"requestBody": {
"description": "Pet documentation or picture to upload",
"required": true,
"content": {
"application/octet-stream": {
"schema": {
"type": "string",
"format": "binary"
}
}
}
},
"responses": {
"201": {
"description": "File uploaded successfully",
"content": {
"application/json": {
"schema": {
"type": "object",
"properties": {
"fileName": {
"type": "string"
},
"uploadedAt": {
"type": "string",
"format": "date-time"
},
"fileSize": {
"type": "integer"
}
}
}
}
}
},
"400": {
"description": "Invalid input, file type not supported"
},
"default": {
"description": "unexpected error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/Error"
}
}
}
}
}
}
}
},
"components": {
"schemas": {
"Pet": {
"type": "object",
"required": [
"id",
"name"
],
"properties": {
"id": {
"type": "integer",
"format": "int64"
},
"name": {
"type": "string",
"pattern": "^[a-zA-Z0-9 ]+$"
},
"tag": {
"type": "string"
},
"status": {
"type": "string",
"enum": [
"available",
"pending",
"sold",
null
],
"nullable": true
}
}
},
"Pets": {
"type": "array",
"items": {
"$ref": "#/components/schemas/Pet"
}
},
"Error": {
"type": "object",
"required": [
"code",
"message"
],
"properties": {
"code": {
"type": "integer",
"format": "int32"
},
"message": {
"type": "string"
}
}
}
}
}
}